Cloud adoption is on the rise and for good reasons. The simplified application hosting and delegated resource management provides companies and individuals the security of a monitored infrastructure, combined with the ease of access to computing resources. Still, these features come at a cost, and cloud computing is not a cheap endeavor.
In order to reduce the cloud computing budget, many organizations decide to run their production environments on the cloud while maintaining quality environments in premises. It would be easy to overlook the necessity of proper resource monitoring, since the cloud has accustomed us to its resilience and fault tolerance. However, doing so could potentially lead to data loss and hours spent on system recovery. In this article we focus on monitoring the health of our infrastructure building blocks, the hard disk drives [HDD]s.
Self-Monitoring, Analysis and Reporting Technology System: the SMART approach.
The truth is all drives will eventually fail. Our objective is, therefore, to collect and interpret the signs and symptoms an HDD shows before failing, so that we can be ready for that event. To do so, Self-Monitoring, Analysis and Reporting Technology System (SMART) built into the most modern disks, can be of assistance. This system reports internal information about the drive, including failure events. Among these, an increase in the following metrics indicates impending HDD failure:
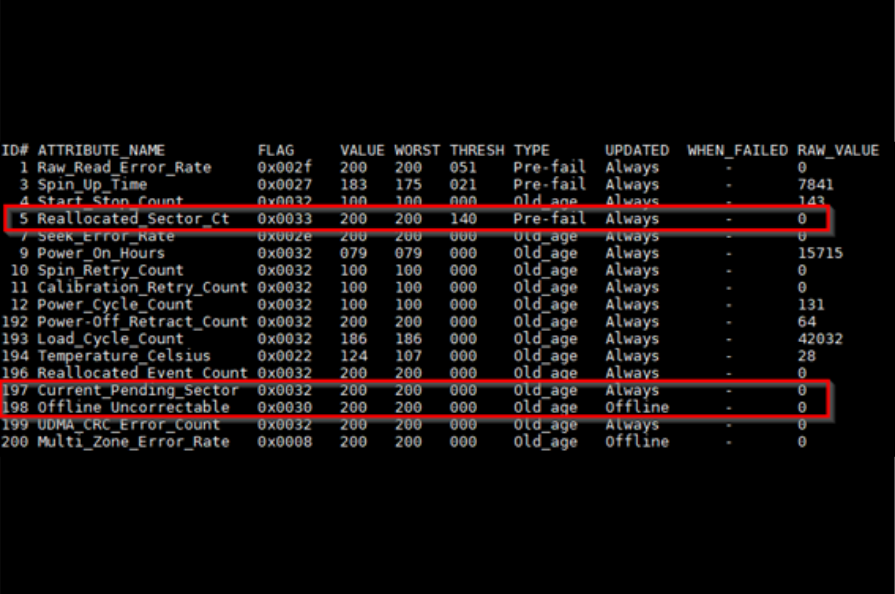
- SMART 5: Reallocated_Sector_Count.
- SMART 197: Current_Pending_Sector_Count.
- SMART 198: Offline_Uncorrectable.
For monitoring these metrics and conducting HDD tests, SMART tools like SmartMonTools can be used. These programs allow the definition of disk analysis on pre-defined schedules, interpret metric results and notify the system administrator in case of detected failures.
A typical report of a healthy drive consists of two parts. Firstly, the HDD information section, where it is important to make sure that the SMART support is available and enabled.

And then, the metrics report, where an increase on critical metrics should be closely monitored by the system administrator, and, if needed, replace the affected disk.
What about failure?
It is important to notice that a single error does not mean the drive is about to fail. A small number of failure events occurs during the HDD lifetime, however, a sudden spike or fast increase over a short time span of the before mentioned critical metrics, is a strong indicator of impending disk failure.
Although these tools are a very important part of a successful infrastructure, always remember that they are here to prevent outages on your system and backups are still essential.
Tiago Diogo
Software Engineer
Support Links: Cloud computing – statistics on the use by enterprises
Contact us to know more about IT Services.